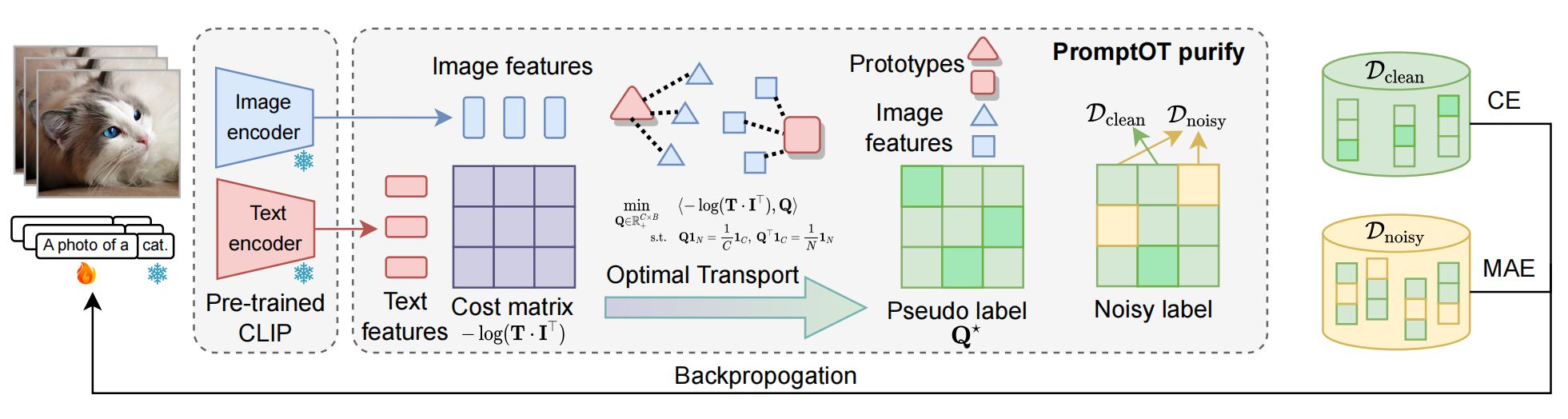
Experimental Results
Performance on Synthetic Noisy Datasets
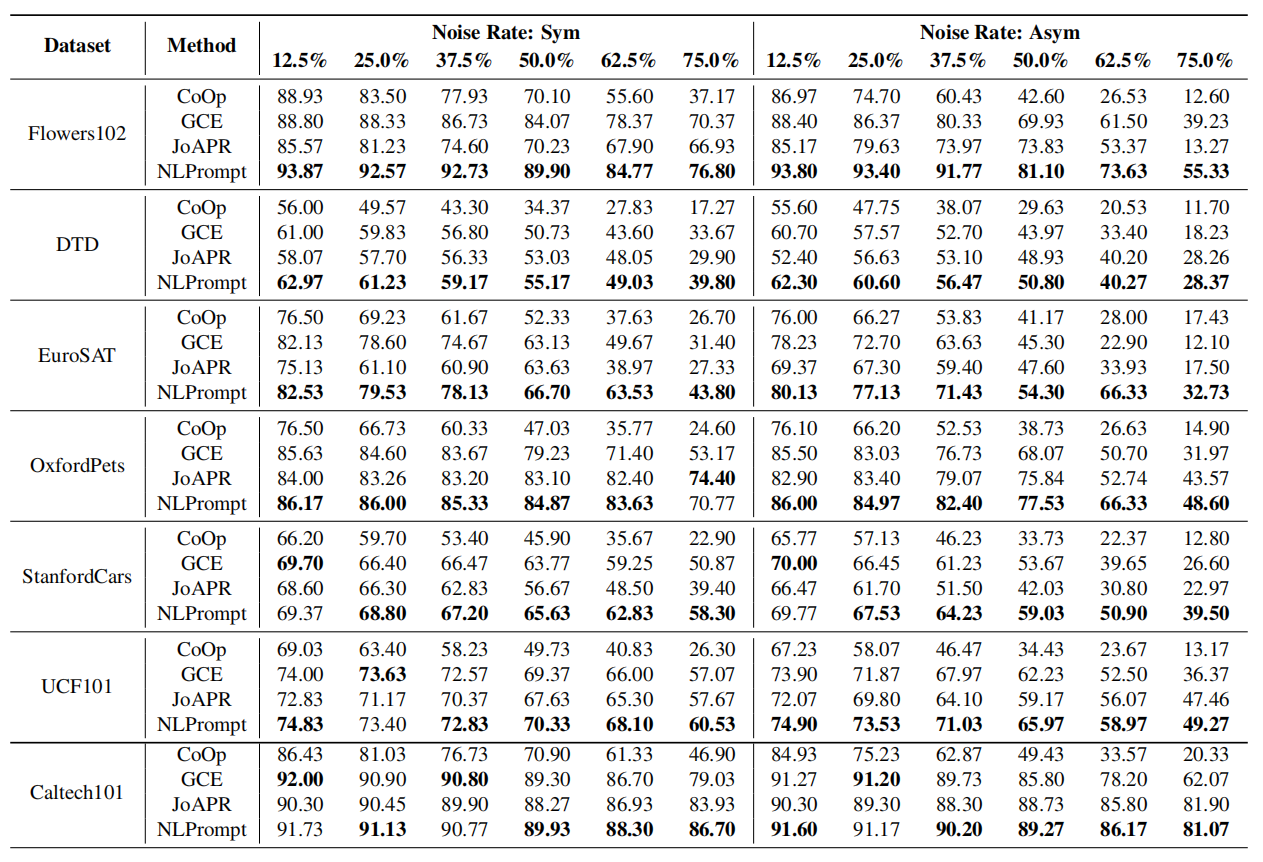
On seven benchmark datasets with varying levels of symmetric and asymmetric noise, NLPrompt consistently achieves state-of-the-art performance, demonstrating significant improvements over existing methods, especially in high-noise scenarios.
Performance on Real-World Noisy Dataset
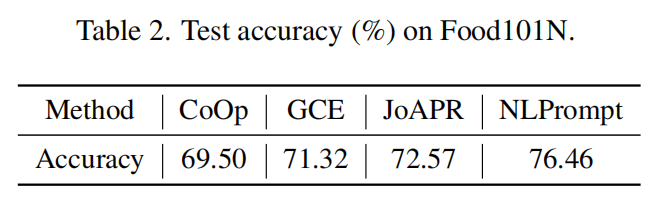
On the real-world noisy dataset Food101N, NLPrompt outperforms all baseline methods, further validating its effectiveness and practical applicability.
Generalization of NLPrompt
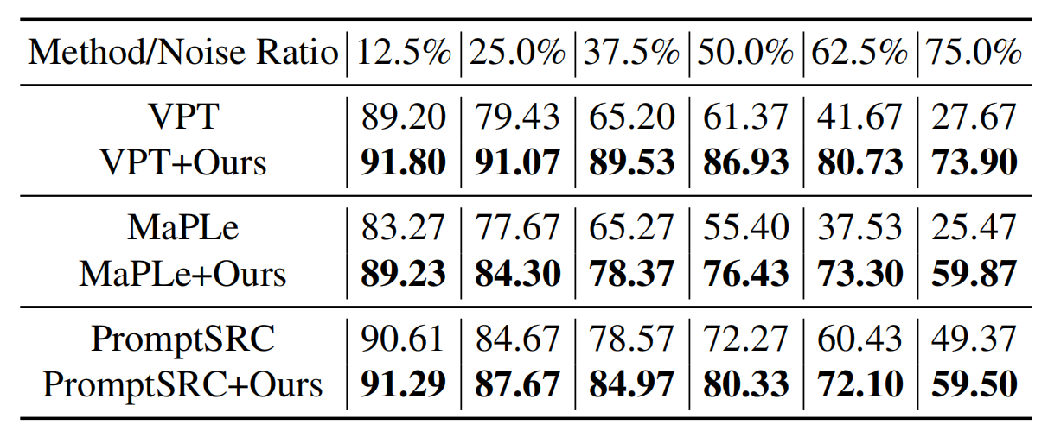
NLPrompt is not limited to CoOp. It can be seamlessly integrated with other advanced prompt tuning methods like VPT, MaPLe, and PromptSRC, consistently boosting their robustness against noisy labels and showcasing its strong generalization capability.
Ablation Studies
We conducted ablation studies on the Flowers102 dataset to validate the effectiveness of each component in our framework.
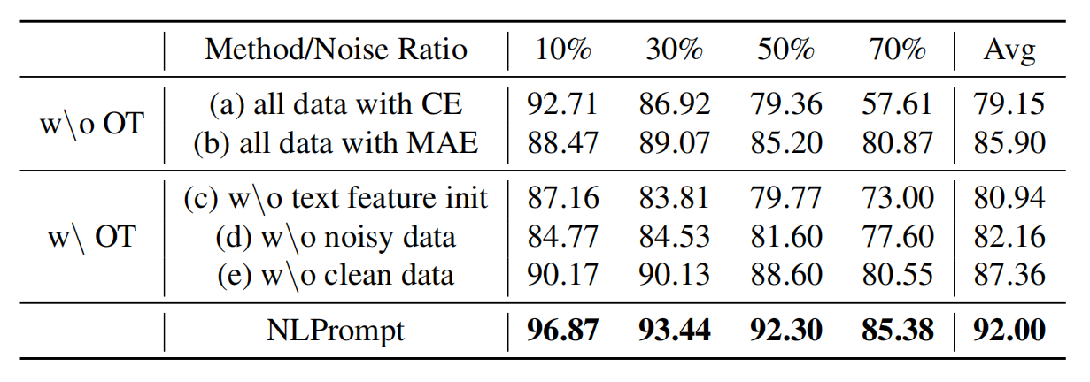
The key findings are:
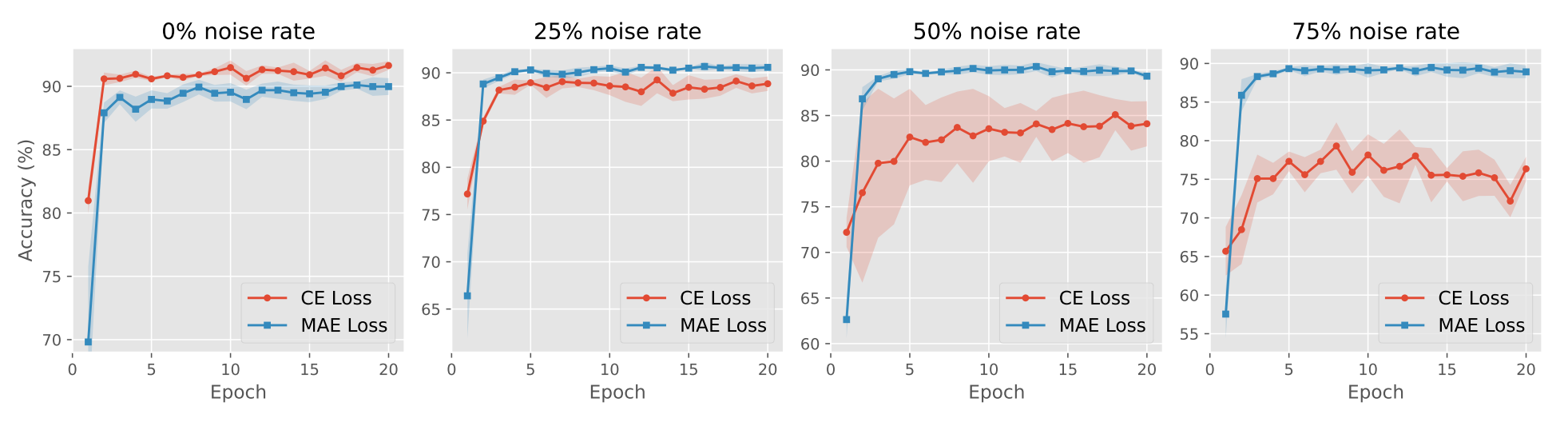
- Using MAE loss for all data (b) outperforms using CE loss for all data (a), confirming the effectiveness of PromptMAE.
- Separately training on the purified clean subset (d) and noisy subset (e) yields better results than training on the whole dataset, validating the efficacy of our PromptOT purification process.
- Our full NLPrompt method significantly outperforms a variant using random initialization (c), highlighting the importance of using semantic text features as OT prototypes.
Overall, the results confirm that every component of NLPrompt contributes to its superior performance.